
Collaborators       |



|
|
Research Statement: Imagination Inspired Computer Vision
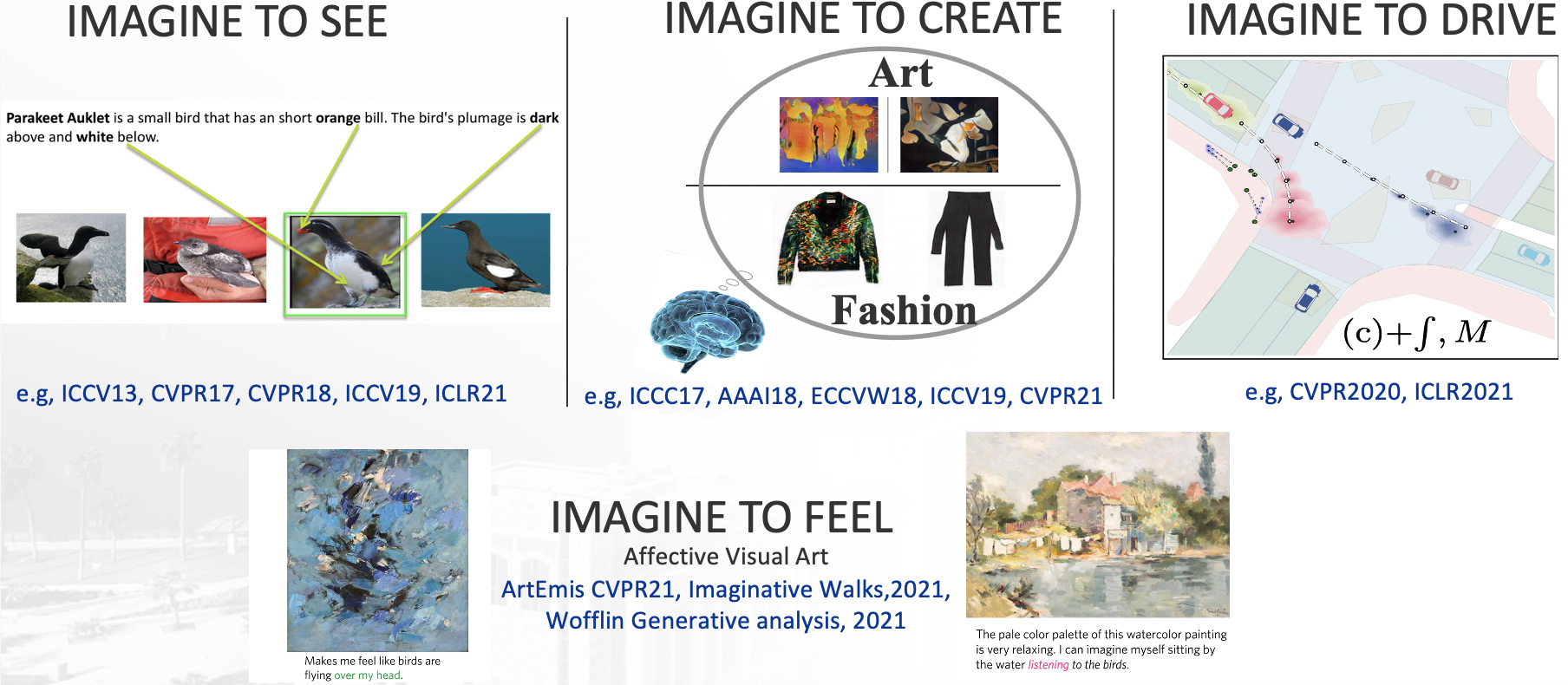
Imagination is one of the key properties of human intelligence that enables us not only to generate creative products like art and music but also to understand the visual world. My research focuses mostly on developing imagination-inspired techniques that empower AI machines to see (computer vision) or to create (e.g., fashion and art); “Imagine to See” and “Imagine to Create”.
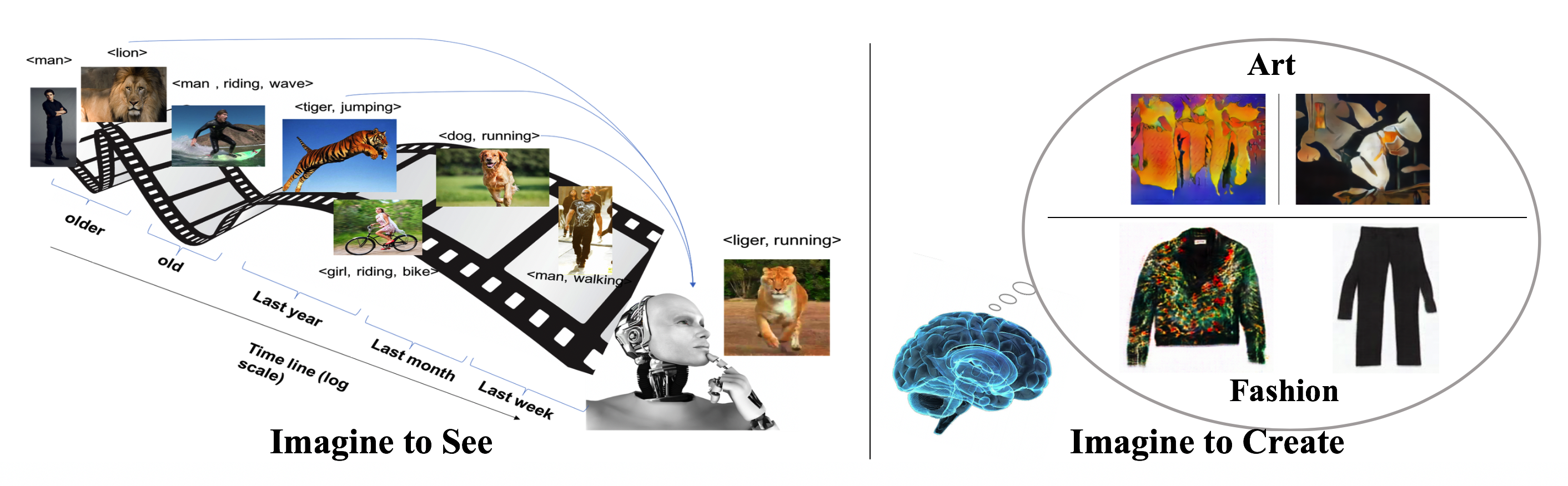
Imagine to See. There are over 10,000 living bird species, yet most computer vision datasets of birds have only 200-500 categories. Typically, there are few images available for training classifiers for most of these categories (long-tail classes) and hence the number of training images per category shows a Zipf distribution [25]. How could imagination help understand visual classes with zero/few examples? Many people might not know what “Parakeet Auklet” is but can imagine it when described in language by saying that “Parakeet Auklet is a bird that has an orange bill, dark above and white below.”. If we give this description to an average person, he will be able to select the relevant bird among other different birds, due to our capability to imagine the “Parakeet Auklet” class from the language description. I have worked on setting up tasks that are inspired by imagination to study visual recognition of unseen classes and long-tail classes guided by language. Since ICCV2013, I have proposed and pioneered the “Write a Classifier” task [8,13,16,17,44] which got recently recognized at the United Nations conference on biodiversity[45]. Recently expanding from the “Sherlock” model and dataset I proposed at AAAI17 [20,21,46], I have been working on developing methods with a deeper understanding and a capacity to learn an ever-growing set of concepts [23,24] (covered by the media); see the figure (left). Learning millions of these concepts impacts not only our relevant content experiences on Google and Facebook but also gets us closer to helpful robots that are continually learning like us about the visual world.
Imagine to Create. Imagination has been the source of novel ideas that enable humanity to progress at an ever-faster rate. Creative AI is a relatively understudied direction in machine learning where the goal is for machines to generate original items with realistic, aesthetic and/or thoughtful attributes, usually in artistic contexts. In the short term, Creative AI has a high potential to speed up our rate of generating creative products like paintings, music, animations, etc. as a source of inspiration. As I detail later, I have worked on modeling Creative AI to produce art [18] and fashion [19]; see the figure (right). Our pioneering creativity work grabbed attention from the scientific community, media, and industry. One of the exciting results we achieved in [19] is that our model was able to create new pants with additional arm sleeves (non-existing in the dataset). The surprising aspect of this design is that professional fashion designers found it inspirational for designing new pants, showing how creativity may impact the fashion industry. I am also excited about future exploration of Creative AI in producing 3D models, videos, and animation. It also may help imagine unseen likely dangerous situations to make self-driving cars more reliable.
Sherlock (2016-present)  Goal Scalable Fact Learning images (objects, attributes, actions, and interactions), publications at AAAI2017 and ACLW2016 Write a Classifier (2013-present) Goal Language Guided Visual Perception of object categories by pure text articles. publications at ICCV 2013, CVPRW 2015, EMNLPW 2015, TPAMI 2016, ongoing work. |
- Write a Classifier Project: Zero Shot Learning from Pure Text description for Fine-Grained Categories, ICCV13, ICCVW13, TPAMI15(to be submitted).
- Hypergraph based approach for Zero-Shot Learning, N-Shot Learning, and Attribute Prediction, CVPR 2015
- Image Classification and Matching by local descriptors (e.g. SIFT), ICIP13
- Joint Category and Pose Recognition with Deep Neural Networks, submitted
- Weather Classification using Convolutional Neural Networks, ICIP, 2015
- Structured Regression: Structured Regression Methods applied to 3D Pose Estimation, Image Reconstruction, Toy Examples, Machine Learning Journal (accepted).
- English2MindMap: Pure Text In- Hierarchical Pictorial Visualization Out, SWWS09, ISM12, MTAP15.
- Undergraduate-Research Mentored Projects (2007-2011),
- Activity Recognition and Motion Characterization, CVPRW13
- Undergraduate-Research Mentored Projects (2007-2011), IPCV09
References
1. M. Elhoseiny, J. Liu, H. Cheng, H. Sawhney, A. Elgammal, “Zero Shot Event Detection by Multimodal Distributional Semantic Embedding of Videos”, AAAI, 2016, acceptance rate 25.6%.
2. A. Baky, T. El-Gaaly, M. Elhoseiny, A. Elgammal, “Joint Object Recognition and Pose Estimation using a Nonlinear View-invariant Latent Generative Mode”, WACV, 2016, algorithms track acceptance rate 30%.
3. M. Elhoseiny, A. Elgammal, “Overlapping Domain Cover for Scalable and Accurate Kernel Regression Machines”, BMVC (oral), 2015, oral acceptance rate 7%.
4. M. Elhoseiny, S. Huang, A El.gammal, “Weather Classification with deep Convolutional Neural Networks”, ICIP, 2015
5. M. Elhoseiny, A. Elgammal, “Generalized Twin Gaussian Processes using Sharma-Mittal Divergence”, Machine Learning journal, 2015
6. S. Huang, M. Elhoseiny, A. Elgammal, “Learning Hypergraph-regularized Attribute Predictors”, CVPR, 2015 (28.4%)
7. M. Elhoseiny, A. Elgammal, B. Saleh, “Tell and Predict: Kernel Classifier Prediction for Unseen Visual Classes from Unstructured Text Descriptions”, Arxiv, 2015, presented in CVPR15 and EMNLP15 Workshosp on Language and Vision.
8. M. Elhoseiny, B. Saleh, A. Elgammal, “Write a Classifier: Zero Shot Learning Using Purely Textual Descriptions”, ICCV, 2013 (27.8%)
9. M. Elhoseiny, B. Saleh, A. Elgammal, “Heterogeneous Domain Adaptation: Learning Visual Classifiers from Textual Description”, VisDA Workshop, ICCV, 2013 (presentation)
10. M. Elhoseiny, S. Cohen, W. Chang, B. Price, A. Elgammal, “Sherlock: Modeling Structured Knowledge in Images”, AAAI, 2017
11. M. Elhoseiny, T. El-Gaaly, A. Bakry, A. Elgammal, “A Comparative Analysis and Study of Multiview Convolutional Neural Network Models for Joint Object Categorization and Pose Estimation”, ICML, 2016
12. A. Bakry, M. Elhoseiny, T. El-Gaaly, A. Elgammal, “Digging Deep into the layers of CNNs: In Search of How CNNs Achieve View Invariance”, ICLR, 2016
13. M. Elhoseiny, A. Elgammal, B Saleh,“Write a Classifier: Predicting Visual Classifiers from Unstructured Text Descriptions”, TPAMI, 2016
14. M.Welling, “Are ML and Statistics Complementary” http://www.ics.uci.edu/~welling/publications/papers/WhyMLneedsStatistics.pdf, 2015
15. Reed, S, Z Akata, X. Yan, Lajanugen Logeswaran, B. Schiele, and H. Lee. "Generative adversarial text to image synthesis.", ICML, 2016
16. M. Elhoseiny*, Y. Zhu*, H. Zhang, A. Elgammal, Link the head to the "peak'': Zero Shot Learning from Noisy Text descriptions at Part Precision, CVPR, 2017
17. Y. Zhu, M. Elhoseiny, B. Liu, A. Elgammal “Imagine it for me: Generative Adversarial Approach for Zero-Shot Learning from Noisy Texts”, CVPR 2018
18. A. Elgammal, B. Liu, M. Elhoseiny, M. Mazzone, “CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms”, International Conference on Computational Creativity, 2017
19. O. Sbai, M. Elhoseiny, C. Couprie, and Y. LeCun, “DesIGN: Design Inspiration from Generative Networks”, ECCVW18, best paper award, JMLR submission, 2018
20. M. Elhoseiny, S. Cohen, W. Chang, B. Price, A. Elgammal, “Automatic Annotation of Structured Facts in Images”, ACL Proceedings of the Vision&Language Workshop, 2016
21. M. Elhoseiny, S. Cohen, W. Chang, B. Price, A. Elgammal, “Sherlock: Scalable Fact Learning in Images”, AAAI, 2017
22. R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, T. Tuytelaars. “Memory Aware Synapses: Learning what (not) to forget”, ECCV, 2018.
23. M. Elhoseiny, F. Babiloni, R. Aljundi, M. Rohrbach, T. Tuytelaars. “An Evaluation of Large-Scale Lifelong Fact Learning”, ACCV, 2018
24. A. Elgammal, B. Liu, D. Kim, M. Elhoseiny, M. Mazzone, “The Shape of Art History in the Eyes of the Machine", AAAI, 2018
25. R. Salakhutdinov, A. Torralba, J. Tenenbaum, “Learning to Share Visual Appearance for Multiclass Object Detection”, CVPR, 2011
28. https://www.technologyreview.com/s/608195/machine-creativity-beats-some-modern-art/
30. C. Martindale. “The clockwork muse: The predictability of artistic change.” Basic Books, 1990.
31. Antol, S., A., Lu, J., Mitchell, M., Batra, D., L. Zitnick, C. and Parikh, D., 2015. Vqa: Visual question answering. ICCV, 2015
32. Das, A., Kottur, S., Gupta, K., Singh, A., Yadav, D., Moura, J.M., Parikh, D. and Batra, D.. Visual dialog, CVPR, 2017
33. https://i.pinimg.com/originals/df/fe/a0/dffea08fdeda5fb3d4e241fc8d8cf538.jpg
{kind=link}
34. Zhu, J. Y., Park, T., Isola, P., & Efros, A. A.. Unpaired image-to-image translation using cycle-consistent adversarial networks, ICCV, 2017
35. https://sites.google.com/site/digihumanlab/products-services
36. https://publishingperspectives.com/2017/10/frankfurt-book-fair-arts-equals-tech-innovation/
37. Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, & Bengio, Y. Generative adversarial nets, NIPS, 2014
38. Andreas, J., Rohrbach, M., Darrell, T., & Klein, D. Neural module networks, CVPR, 2016
39. Hu, R., Andreas, J., Rohrbach, M., Darrell, T., & Saenko, K. End-to-end module networks for visual question answering, ICCV, 2017
40. Johnson, J., Hariharan, B., van der Maaten, L., Hoffman, J., Fei-Fei, L., Zitnick, C. L., & Girshick, R. Inferring and Executing Programs for Visual Reasoning, ICCV, 2017
41. A. Chaudhry, M. Ranzato, M. Rohrbach, M. Elhoseiny, “Efficient Lifelong Learning with A-GEM”, ICLR submission, 2019
42. S. Ebrahimi, M. Elhoseiny, T. Darrell,M. Rohrbach, “Uncertainty-guided Lifelong Learning in Bayesian Networks”, ICLR submission, 2019
43. M. Elfeki, C. Couprie, M. Elhoseiny, “Learning Diverse Generations using Determinantal Point Processes”, ICLR submission, 2019
44. M Elhoseiny, M Elfeki, “Creativity Inspired Zero Shot Learning”, CVPR, 2019 submission
45. https://www.facebook.com/UNBiodiversity/videos/2221370044851625
46. J. Zhang, Y. Kalantidis, M. Rohrbach, M Paluri, A. Elgammal, M Elhoseiny. Large-Scale Visual Relationship Understanding, AAAI, 2019