
This dataset has two parts. You can use the part you need. A) Structured COCO Facts. B) Structured Flickr30K Facts. For instance, these data could be use as an automatically augmented facts for MS COCO dataset and hence can help access fact level data to improve captioning. Goal: Collecting data for the space of visual actions and interaction is huge, so we propose to collect such data guided by captions. 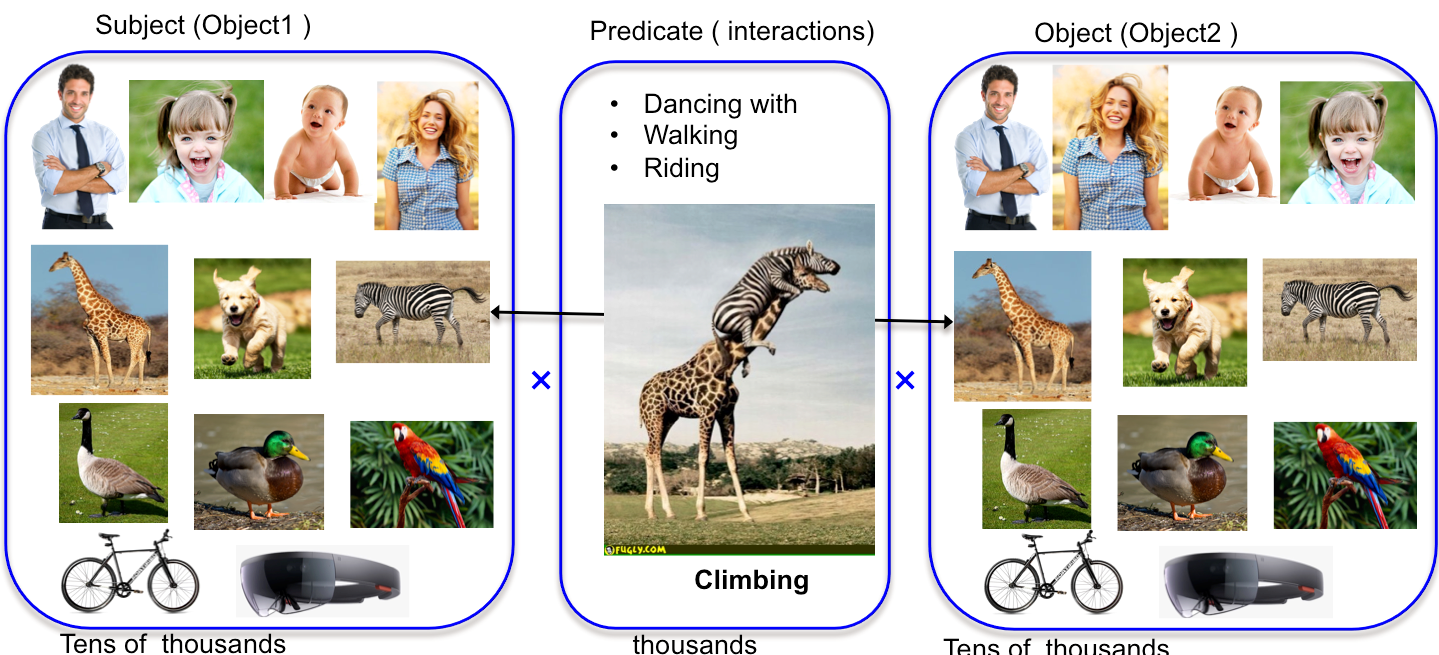 How it works, please refer to the paper for details. 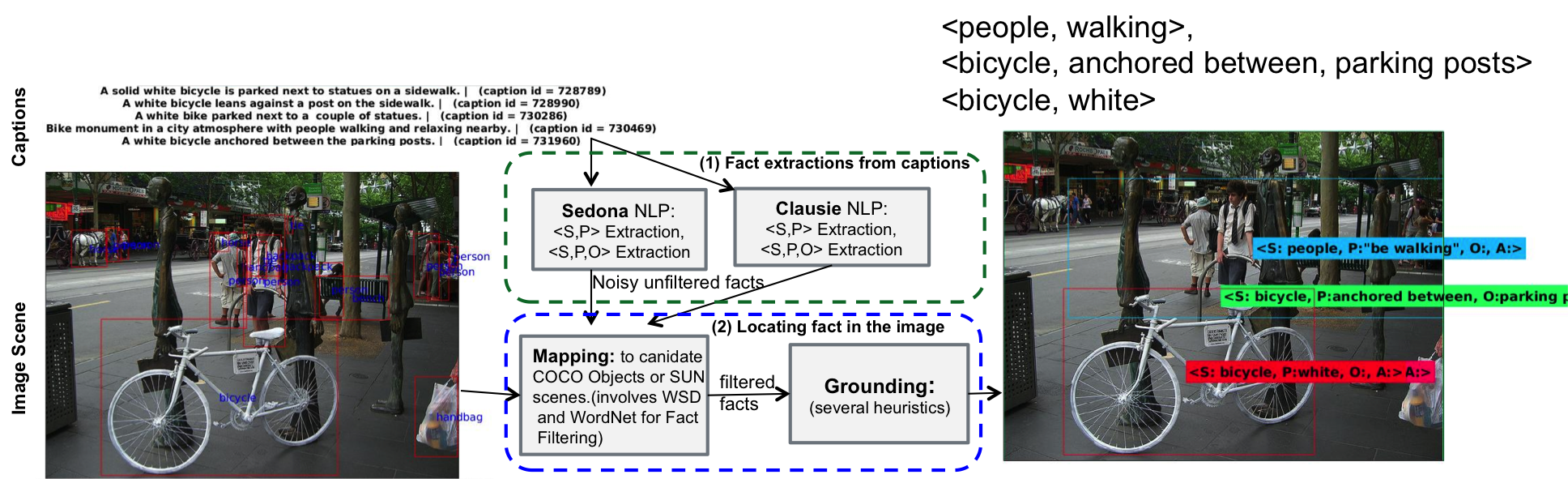 Motivated by the application of fact-level image understanding, we present an automatic method for data collection of structured visual facts from images with captions. Example structured facts include attributed objects (e.g., <flower, red>), actions (e.g., <baby, smile>), interactions (e.g., <man, walking, dog>), and positional information (e.g., <vase, on, table>). The collected annotations are in the form of fact-image pairs (e.g.,<man, walking, dog> and an image region containing this fact). With a language approach, the proposed method is able to collect hundreds of thousands of visual fact annotations with accuracy of 83% according to human judgment. Our method automatically collected more than 380,000 visual fact annotations and more than 110,000 unique visual facts from images with captions and localized them in images in less than one day of processing time on standard CPU platforms. Download Data collected by the Method from MSCOCO and Flickr30K datasets Version 1 (Light) Version 1 (More Detailed). I prepared the annotations on dropbox. It was actually few hundred megabytes. I am trying to illustrate the annotations in this email. You can always get back to me for any questions as well. I try to ground subjects/objects that is either coco object or one of sun dataset scenes.
Train 2014
Val 2014
coco senses. https://dl.dropboxusercontent.com/u/33950950/sherlock_project/detailed_auto_data/coco_senses.mat
Sun Scene https://dl.dropboxusercontent.com/u/33950950/sherlock_project/detailed_auto_data/scene_names.mat
README for Version1 (More detailed) AllGroundedData{i} has the annotations for the ith image in coco
AllGroundedData{i}.imId is the cocoid AllGroundedData{i}. UncleanedGroundedData is the list for grounding data at this image.
Each element inside AllGroundedData{i}. UncleanedGroundedData is a grounded example, that has the following info tuple: <subject, predicate, object> 1) statement_ID: if of the statement from which this tuple is extracted 2) type: S/SP/SPO 3) GroundingInfo: has inside it, some properties detailed below. i) tuple_bbox : is the box associated ii) object_bboxes: caindate boxes in the image that match object type iii) subject_bboxes: caindate boxes in the image that match subject type iv) is_subject_scene: 1 if subject is scene v) is_object_scene : 1 if object is scene vi) linkingData a. subjectInfo i. linkedObjectsIndeces: [1] if for person, it will be a number between 2 and 80 for other coco objects. ii. linkedSceneIndex: is sun scene will include the scene index iii. isPlural: if subject is plural iv. assigned: if subject is grounded (can find some annotation in coco that matches its type. b. objectInfo i. linkedObjectsIndeces: [1] if for person, it will be a number between 2 and 80 for other coco objects. ii. linkedSceneIndex: is sun scene will include the scene index iii. isPlural: if objecr is plural iv. assigned: if object is grounded (can find some annotation in coco that matches its type. vii) complete_assignment=1, if we manage to assign all elements viii) TH: you can use all annotations with TH=-1. Some times, when I am not able to locate one of the interacting object/subject, I assign the tuple_bbox in (i) above to the whole image. TH in this case will have the ratio between the subject/object I found and the total image area (i.e. TH = object_found_area/ (W*H). I found it good to use tuple_bbox as an annotation for the whole interaction with TH>0.3. However, You can still find the box that contain the object/subject only
Papers / Citation If you find this data useful, please consider citing @inproceedings{elhoseiny2016automatic, title={Automatic Annotation of Structured Facts in Images}, author={Elhoseiny, Mohamed and Cohen, Scott and Chang, Walter and Price, Brian and Elgammal, Ahmed}, booktitle={ACL 2016 (Vision&Language long-paper workshop proceedings)}, year={2016}}
|